![]()
Datenanalyse mit Python¶
Dr. Yves J. Hilpisch
The Python Quants GmbH
Köln, 5. Quantified Self Meetup – 27. März 2014
Über Mich¶
Im Überblick:
- Geschäftsführer der The Python Quants GmbH
- Gründer der Visixion GmbH – The Python Quants
- Lehrbeauftragter Mathematical Finance an der Universität des Saarlandes
- Fokus auf die Finanzindustrie und Financial Analytics
- Buch (2013) "Derivatives Analytics with Python"
- Buch (2014) "Python for Finance", O'Reilly
- Dr.rer.pol in Mathematical Finance
- Diplom-Kaufmann
- Kampfkunst und -sport
Vgl. auch www.hilpisch.com.

Typische Probleme in der Datenanalyse¶
Jeder der mit Daten arbeitet, trifft auf ein oder mehrere Probleme aus der folgenden Liste:
- Quellen: Daten kommen im Allgemeinen aus unterschiedlichen Quellen, wie z.B. SQL-Datenbanken, Excel-Dateien oder CSV-Dateien
- Formate: selbst Daten aus der gleichen Quelle, z.B. CSV-Datei, können stark unterschiedlich formattiert sein (z.B. Semikolon statt Komma)
- Struktur: selbst Daten die aus der gleichen Quelle und im gleichen Format kommen, z.B. als CSV-Datei, können stark unterschiedliche Strukturen (z.B. einfacher Index vs. Multi-Index) aufweisen
- Vollständigkeit: Daten aus der realen Welt sind, gegeben einen Benchmark (Zeit-)Index, nicht immer vollständig; zwei Zeitreihen können eine unterschiedliche Anzahl an Datenpunkten aufweisen
- Konventionen: bestimmte Daten, wie z.B. Datum- und Zeitangaben, werden häufig nach stark unterschiedlichen Konventionen abgespeichert (z.B. Tag zuerst vs. Monat zuerst)
- Interpretation: einige Standarddaten, wie z.B. Datum- und Zeitangaben, sollten einfach und automatisiert zu interpretieren sein
- Performance: bei großen Datenmengen sollte das Processing von Datan performant von statten gehen
Eine grundlegende Python-Installation für die Datenanalyse umfasst mindestens die folgenden Pakete:
- Python – der Python-Interpreter selbst
- NumPy – performante und flexible Array-Operationen
- SciPy – Sammlung an wissenschaftlich-mathematischen Funktionen
- pandas – Bibliothek zur effizienten Analyse von Zeitreihendaten
- PyTables – hierarchische, performante Datenbanktechnologie
- matplotlib – 2d und 3d Visualisierung
- IPython – interaktive Umgebung für Datenanalyse und Ergebnispublikation
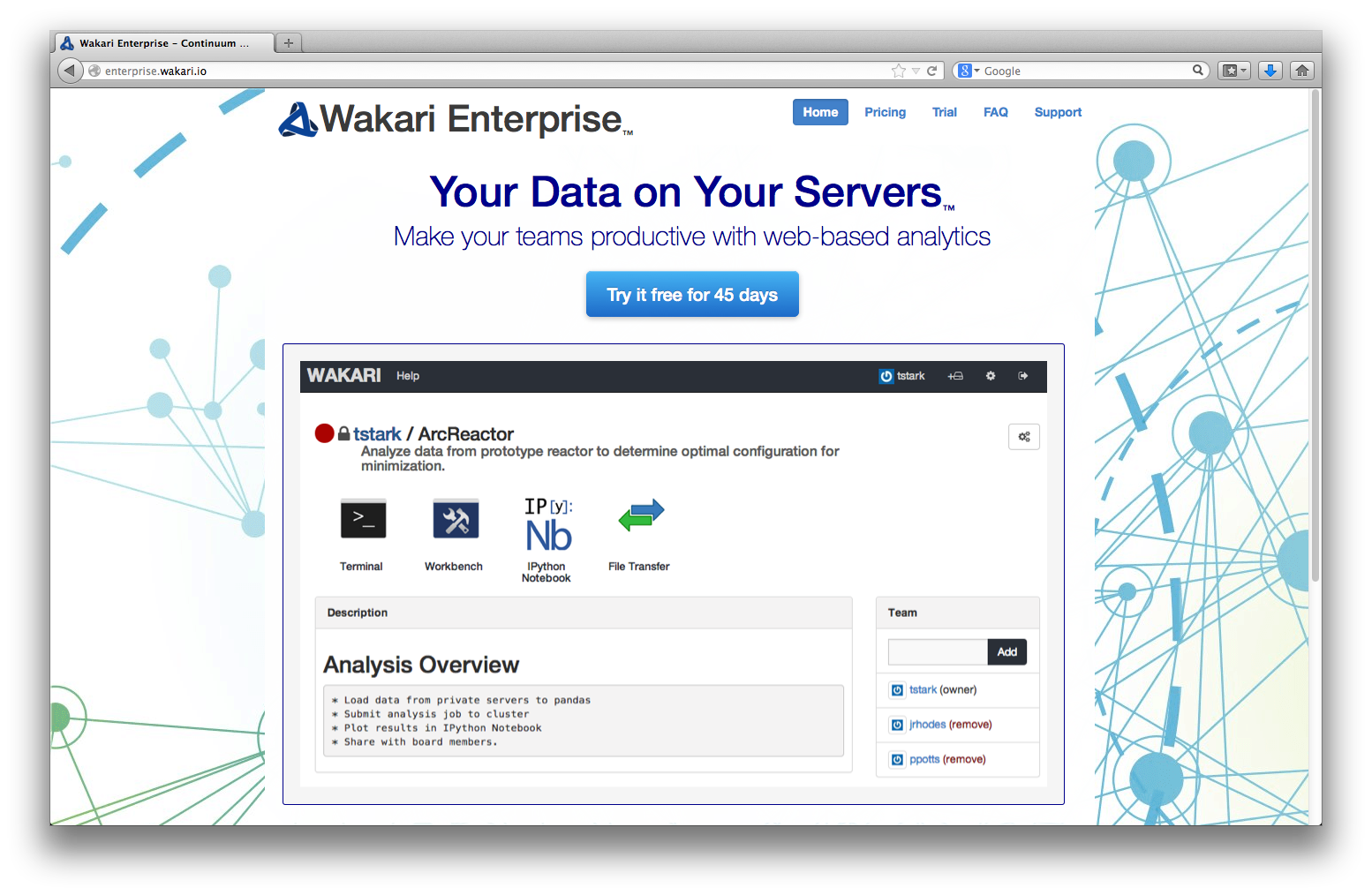
Am besten nutzt man die Anaconda Distribution oder die Web-basierte Data Analytics Platform Wakari. Beide bieten "vollständige" Python-Umgebungen für die Datenanalyse.
Analyse von Quantified Self-Daten¶
Alle Datensätze zur Verfügung gestellt von Andreas Schreiber. Mein Dank an dieser Stelle.
Die Daten – Schritte über ein Jahr¶
Zur Verfügung haben wir einen Datensatz aus einem Fitbit One Activity-Tracker. Die Daten liegen in dem Standardformat "Comma Separated Values" (CSV) vor (= ein Textfile).
Wie öffnen die Datei zum Lesen.
f = open('./data/schritte.csv', 'r')
Der Inhalt kann Zeile für Zeile gelesen und am Bildschirm ausgegeben werden.
for l in range(6):
print f.readline(),
pandas ist eine speziell für derartige Daten entwickelte Python-Bibliothek.
import pandas as pd
# pandas Bibliothek
import numpy as np
# NumPy Bibliothek
%matplotlib inline
# Plots in IPython Notebook
Daten Einlesen¶
Die Funktion read_csv erlaubt wertvolle Parametrisierungen für das Einlesen von Daten, die in unterschiedlichen Formaten vorliegen.
schritte = pd.read_csv('./data/schritte.csv', # filename
header=1, # header Reihe
index_col=0, # index Spalte
parse_dates=True, # index als Datum
dayfirst=True, # Tag zuerst (Europa)
decimal=',', # Dezimalzeichen
thousands='.') # Tausenderzeichen
Alle Daten sind nun als pandas DataFrame-Objekt im Speicher.
schritte.info()
Daten Ausgeben¶
Die Daten können nun z.B. tabellarisch ausgegeben werden.
schritte.ix[100:105]
Häufig benötigte Statistiken können leicht abgefragt werden.
np.round(schritte.describe(), 1)
Bestimmte Zeiträume lassen sich einfach selektieren.
np.round(schritte[(schritte.index > '2014/1/1')
& (schritte.index < '2014/1/31') ].describe())
# nur Januar 2014 Daten
Daten Visualisieren¶
Ebenso können die Daten nun sehr leicht visualisiert werden (I).
schritte[['Schritte', 'Strecke']].plot(subplots=True, style='b', figsize=(10, 5))

Ebenso können die Daten nun sehr leicht visualisiert werden (II).
schritte[['Schritte', 'Strecke']].hist(bins=30, figsize=(10, 4))

Die Daten lassen sich auch mit weiteren Zeitreihen, z.B. gleitenden Durchschnitten anreichern.
schritte['gldStrecke'] = pd.rolling_mean(schritte['Strecke'], 30)
schritte[['Strecke', 'gldStrecke']].plot(figsize=(10, 4), style=['g', 'r'])

Komplexere Analysen¶
Wir wollen nun die Aktivität in Abhängigkeit des Wochentags analysieren. Dazu reichern wir den Datensatz um Wochentage an (0 = Montag, 6 = Sonntag).
schritte['Wochentag'] = schritte.index.weekday
schritte[['Schritte', 'Wochentag']].ix[200:205]
Zur besseren "menschlichen" Lesbarkeit ergänzen wir die Zahlen durch Abkürzungen für den Wochentagnamen.
schritte['Wochentag'].replace(to_replace=[0, 1, 2, 3, 4, 5, 6],
value=['0_Mon', '1_Die', '2_Mit', '3_Don', '4_Fre', '5_Sam', '6_Son'],
inplace=True)
schritte[['Schritte', 'Wochentag']].ix[200:205]
Nun können wir nach Wochentragen gruppieren ...
grouped = schritte.groupby(['Wochentag'])
... und können uns z.B. den durchschnittlichen Wert je Wochentag ausgeben lassen.
np.round(grouped[['Schritte', 'Strecke']].mean(), 2)
Auch diese Daten sind einfach zu visualisieren.
grouped['Aktivitätskalorien'].mean().plot(kind='barh', grid=True)

Datenspeicherung¶
Mit pandas kann man ganze DataFrame-Objekte einfach speichern und bei Bedarf wieder einlesen.
# Schreiben der Daten als DataFrame
h5 = pd.HDFStore('./data/schritte.h5', 'w')
h5['schrittdaten'] = schritte
h5.close()
ll ./data/schr*
# Einlesen der Daten
h5 = pd.HDFStore('./data/schritte.h5', 'r')
schritte = h5['schrittdaten']
h5.close()
Weitere Beispiele für Quantified Self-Daten¶
Gewicht¶
Ein weiterer Datensatz enthält Gewichtsangaben im Zeitablauf (von einer Withings WLAN-Waage).
f = open('./data/gewicht.csv', 'r')
for l in range(5):
print f.readline(),
Wiederum lesen wir die Daten mit Hilfe von pandas ein – ohne großartige Parametrisierung.
gewicht = pd.read_csv('./data/gewicht.csv')
gewicht.ix[:5]
Wir bereiten die Datumsangaben etwas auf, damit pandas sie interpretieren kann.
gewicht['Date'] = [date.replace(' Uhr', '') for date in gewicht['Date']]
# lösche " Uhr" in jeder Angabe
from dateutil.parser import parse
gewicht['Date'] = gewicht['Date'].apply(parse)
# übersetze die Angabe in korrektes Datums-Zeit-Format
gewicht.set_index('Date', inplace=True)
# mache die "Date" Spalte zum Index
Die Daten liegen wiederum in dem nun bekannten DataFrame-Format im Datenspeicher vor.
gewicht.info()
gewicht.columns = ['Gewicht', 'Fettmasse', 'Fettfrei', 'Kommentar']
# Umbenennen der Spalten
pandas kümmert sich automatisch um fehlende Daten – Berechnungen sind problemlos auch mit unvollständigen Datensätzen möglich.
np.round(gewicht.describe(), 2)
Graphische Auswertungen sind natürlich nun auch wieder einfach möglich.
gewicht['Gewicht'].plot()

Blutdruck¶
Wie bereits gewohnt, zuerst ein Blick in die Rohdaten für die Blutdruckwerte (von der Applikation BlutdruckBegleiter).
f = open('./data/blutdruck.csv', 'r')
for l in range(5):
print f.readline(),
Wir nutzen wiederum pandas als Allzweckwaffe für das Einlesen von Daten.
blutdruck = pd.read_csv('./data/blutdruck.csv',
index_col=0, # index Spalte
parse_dates=[[0, 1]], # kombiniere Spalte 0 & 1
# zu Datum-Zeit-Index
dayfirst=True) # Tag zuerst (Europa)
Wie löschen 3 Spalten und schauen uns die letzten Angaben an.
del blutdruck['Geraet']
del blutdruck['Kommentar']
blutdruck.tail()
Wir können nun die wesentlichen Werte visualisieren.
blutdruck[['Systolisch', 'Diastolisch', 'Puls']].plot(
subplots=True, style=['b', 'r', 'g'],
figsize=(10, 6))

Um einfacher Trends feststellen zu können, können wir z.B. auch 2-Wochen gleitende Durchschnitte verwenden.
pd.rolling_mean(blutdruck[['Systolisch', 'Diastolisch']], 14).plot(
style=['b', 'r'], figsize=(10, 6))

Warum Python für die Datenanalyse?¶
Am Beispiel der durchweg genutzten Bibliothek pandas kann man dies gut illustrieren:
- Quellen: pandas kann Daten aus unterschiedlichen Quellen einlesen (SQL-Datenbanken, CSV-Dateien etc.)
- Formate: pandas kann unterschiedliche Formate erkennen und einlesen (z.B. unterschiedlich formattierte CSV-Dateien)
- Struktur: pandas erkennt Datenstrukturen und bildet diese intern entsprechend ab (z.B. Zeitindex für Zeitreihendaten sowie Spaltennamen)
- Vollständigkeit: pandas behandelt fehlende Daten automatisch und elegant; man kann mit unvollständigen Datensätzen häufig so arbeiten wie mit vollständigen
- Konvention/Interpretation: pandas kennt z.B. viele unterschiedliche Konventionen für Datumsangaben und interpretiert diese entsprechend
- Performanz: die pandas Klassen, Methoden und Funktionen sind i.d.R. performant implementiert unter Nutzung von z.B. Cython als Python/C-Compiler
Python zeichnet sich darüber hinaus aber auch durch eine Reihe weiterer Merkmale positiv aus:
- Allzweck: Python kann für alles, vom Prototyping bis in die Produktion eingesetzt werden
- Bibliotheken: es gibt eine Masse an wertvollen Bibliotheken für nahezu alle Einsatzbereiche
- Effizienz: nach kurzer Einarbeitung ist man in der Regel sehr effizient im Umgang mit der Sprache und Daten
- Perfomanz: Python macht den Zugriff auf moderne High Performance-Technologie i.d.R. recht einfach (e.g. LLVM, multi-core CPUs, GPUs, clusters)
- Interoparabilität: Python versteht sich gut mit anderen Technologien, Sprachen und Umgebungen
- Interaktivität: Python erlaubt Interaktivität in Echtzeit sowie einfaches Lernen durch "Versuch und Irrtum"
- Zusammenarbeit: Python und Technologien wie Wakari erlauben die einfache Zusammenarbeit von Mehreren und Teams an Datananalyse-Projekten
![]()
The Python Quants GmbH – the company Web site
Dr. Yves J. Hilpisch – my personal Web site
Python for Finance – my NEW book (out as Early Release)
Derivatives Analytics with Python – my new book
www.derivatives-analytics-with-python.com
Contact Us